.jpg)
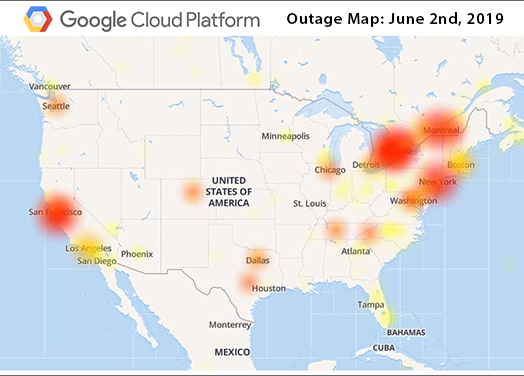
On Sunday, June 2nd, 2019, the "impossible" happened: Google went down.
Not only Google services such as Gmail and YouTube suffered (for free and GSuite customers alike) — so did countless sites and apps powered by Google Cloud, including Snapchat, Vimeo, FreshBooks, and every store powered by Shopify.
Did your Shopify store go down? Let's help you prepare for next time.
This "slow performance" and "intermittent errors" went on for nearly 4 hours.
If even Google can't stay online 24x7, surely small businesses can't either, right? Not true.


What does it mean to have High Availability?
When running an e-commerce website, High Availability means your software & hardware infrastructure is set up in a way that can theoretically never go down just because a single datacenter, cloud region, or backbone ISP goes down.
Wikipedia actually explains it well: There are three principles of systems design in reliability engineering which can help achieve high availability.
- Elimination of single points of failure. This means adding redundancy to the system so that failure of a component does not mean failure of the entire system.
- Reliable crossover. In redundant systems, the crossover point itself tends to become a single point of failure. Reliable systems must provide for reliable crossover.
- Detection of failures as they occur. If the two principles above are observed, then a user may never see a failure – but the maintenance activity must.
Making an existing website or application Highly Available
Step One: Set up a high-availability load balancer such as HAProxy. Theta Labs can help with that. All you have to do is ask.
Step Two: Is your website or application backed by a database? Both MySQL and its sister project MariaDB both support high-availability clusters.
Highly available SQL databases can be tricky to maintain, so please reach out if you need help.
Step Three: Set up a highly-available filesystem using technologies such as Ceph and Gluster
Step Four: Test everything thoroughly. Powerhouse companies like Netflix even have their own tools (ever heard of Chaos Monkey?) meant specifically to wreak havoc on their hosting infrastructure so they can see how their systems perform under stress and how well outages are tolerated.